Everyday apps feed massive AI data collection
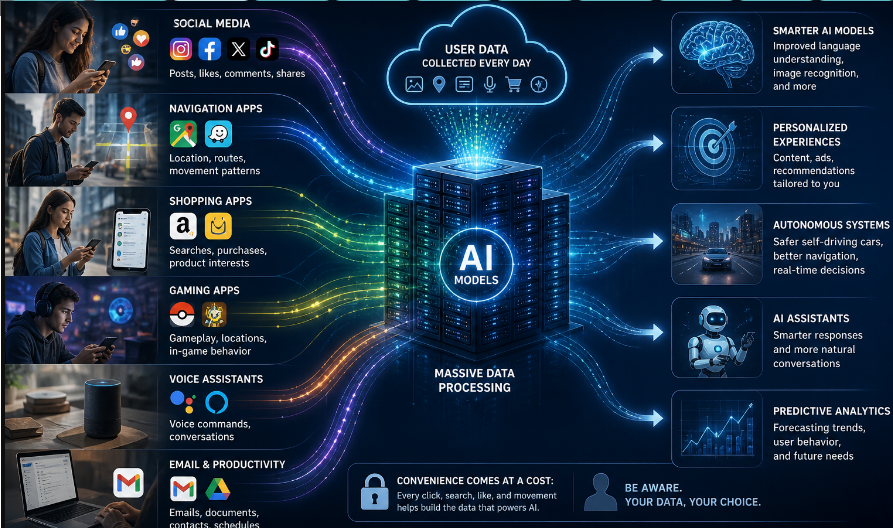
Users are unknowingly playing a role in training artificial intelligence tools through everyday online services they use.
Large language models (LLMs) such as ChatGPT, Gemini, and Claude—capable of generating human-like text—are used daily by millions of people. These models are trained on large volumes of text collected from books, websites, articles, and other written materials, CE Report quotes Anadolu Agency.
Although training data can be gathered from publicly available sources, recent debates have increasingly focused on the extent to which this process also draws on the online behavior of internet users.
CAPTCHA and reCAPTCHA tests, designed to verify that a user is human before accessing online services, are increasingly seen as more than just security tools for tech companies.
These tests, which ask users to identify letters in images or distinguish objects, have long been discussed as potential sources of data for AI training.
The frequent use of images such as pedestrian crossings, traffic lights, and vehicles in Google’s tests has led to claims that the collected data may be used in training AI systems for autonomous driving technologies.
A Google Cloud spokesperson told Anadolu Agency that “reCAPTCHA user data is not used for any purpose other than improving the reCAPTCHA service, and this is clearly stated in the terms of service.”
From mobile games to real-world mapping
Debates over the use of everyday data for AI training have recently expanded to other areas such as video games.
The game “Pokémon Go,” released in 2016 by the US-based company Niantic and quickly becoming globally popular, has recently come under scrutiny.
The game, which encourages players to find Pokémon characters in the real world using GPS and smartphone cameras, has contributed to the creation of a massive dataset of street-level imagery.
According to a report by MIT Technology Review, Niantic’s AI company Niantic Spatial used 30 billion images collected by players to build a realistic virtual model of the real world.
The company stated that it has developed technology allowing users to upload images of their surroundings to locate themselves on a map.
It also aims to use these models to improve robot navigation in areas where GPS is unreliable.
In a November 2024 statement, the company confirmed that player-contributed real-world scanning data is used, but emphasized that the feature is entirely optional.
Users directly contribute to AI improvement
Christian Peukert, professor at the University of Lausanne, discussed the balance between data used in AI training and user privacy in comments to Anadolu Agency.
He explained that earlier versions of CAPTCHA included one word known by the system and another unknown, with user input helping to digitize and improve text recognition systems.
According to Peukert, this means users have been directly contributing to the improvement of text recognition technologies.
He added that much of AI training relies on passive data generated by users online, often without their awareness.
He also noted that social media platforms like Reddit and Twitter provide large datasets for training language models, while image platforms like Instagram contribute labeled visual data through captions and tags.
Search queries from Google help improve language understanding and ranking systems, while navigation apps like Google Maps and Waze collect movement data used to train predictive models. Conversations with chatbots and voice assistants are also often recorded and used to improve systems.
Privacy and security concerns
Peukert warned that these processes raise concerns regarding privacy and security, including risks of profiling, generation of fake content, and users unintentionally feeding systems that may compete with them.
He stressed that individual measures are not sufficient to reduce data usage, noting that most training data has already been collected, duplicated, or made publicly available across systems.
Once data is included in large datasets, regaining control over it becomes extremely difficult, he said.
However, he also acknowledged benefits, pointing out that human-generated data supports language technologies, translation tools, accessibility systems, scientific research, and everyday services such as search engines.






















